# 들어가며
CPU와 GPU의 구조에 대해서 자세하게 배운다. 컴퓨터 구조 관련한 배경지식이 있으면 이해하기 편하므로 글을 읽다가 이해가 되지 않는다면 관련 블로그 포스트나 유튜브를 찾아보는 것이 좋다. 이전 글은 다음 링크의 블로그 포스트를 참고하면 된다.
[인공지능 하드웨어] 2 - DNN Computation
# 들어가며DNN(Deep Neural Networks)가 어떻게 계산되는지 알아보고, 하드웨어에서 어떻게 처리될지 행렬 수준에서 이해해 보도록 하자. 이전 글은 다음 링크의 블로그 포스트를 참고하면 된다. [인공
kmuhan-study.tistory.com
# Background
GPU Architecture를 배우기 앞서, 먼저 관련 배경지식을 점검 해야한다.
- Clock Speed: CPU, GPU의 프로세서가 실행되는 속도를 나타낸다. 클럭 속도가 높을수록 더 빠른 속도로 데이터를 처리할 수 있다.
- Memory Bandwidth: 메모리에서 프로세서로 데이터를 전송할 수 있는 속도이다. 1초에 얼마나 많은 데이터를 전송하는지(GB/s)를 나타낸다. 따라서 Memory Bandwidth가 커지는 것은 GPU가 계산할 때 필요한 데이터를 메모리에서 더 빨리 엑세스 할 수 있다는 것을 의미한다. Memory Bandwidth를 구하는 공식은 다음과 같다.
Memory Bandwidth = Clock Speed(Hz) * Memory Bus Width(bits) * 전송 비율(ex 2배, 3배) - CUDA: NVIDIA에서 2007년 Tesla Architecture과 함께 공개되었다. CUDA core를 통해 딥러닝 분야에서 GPU 병렬 처리 능력을 활용할 수 있다. 관련 라이브러리로 cuDNN(쿠다 딥러닝 라이브러리), TensorRT(양자화 등), DeepStream SDK(아키텍쳐 활용) 등이 있다.
# CPU vs GPU
CPU와 GPU의 대략적인 차이는 다음과 같다.
| CPU | GPU |
| 매우 빠른 수십개의 코어 순차적 실행에 최적화 대용량 캐시를 활용한 지연 시간 최소화 Latency-oriented |
중간 속도의 수천개의 코어 데이터 병렬 실행에 최적화 지연시간을 숨기고 처리량을 극대화 Throughput-oriented |
## CPU Hierarchy
CPU의 계층적 구조는 다음과 같다. 일반적으로 L1, L2, L3 캐시를 가지고 있으며, DDR4 DRAM을 사용하는 Memory의 Memory Bandwidth는 30GB/s정도 된다고 한다. 만약 4개의 코어를 가지는 CPU라면 하나의 코어가 가지는 Memory Bandwidth는 4GB/s정도가 되는 것이다.

## GPU Hierarchy
GPU는 5,000개에서 10,000개 정도의 CPU에 비해서 굉장히 많은 코어를 가지고 있다. L1, L2 캐시의 사이즈가 Streaming Multiprocessor 하나당 128KB, 6MB정도로 CPU에 비해서 훨씬 작고, 하나의 SM 안에 16개 혹은 32개의 코어가 존재할때, 코어 하나당 L1, L2 캐시의 사이즈는 더더욱 작다. 전체적으로 보면 약 1TB 커다란 Memory Bandwidth를 가지고 있지만, 코어 하나당 처리할 수 있는 메모리는 굉장히 작기 때문에 GPU 안에서 명령어를 효율적으로 처리할 수 있는 테크닉들이 많이 사용된다.

## Why GPU?
2010년 이전에는 CPU에서 기하급수적인 성능 향상이 일어났었다. 명령어 수준의 병렬 처리를 도입하였으며, 말 그대로 Technology Scaling이 지수함수적으로 일어났다. 하지만 2010년 이후에는 아키텍쳐 개선의 포화로 매년 3%의 성능 향상만 일어나고 있다.
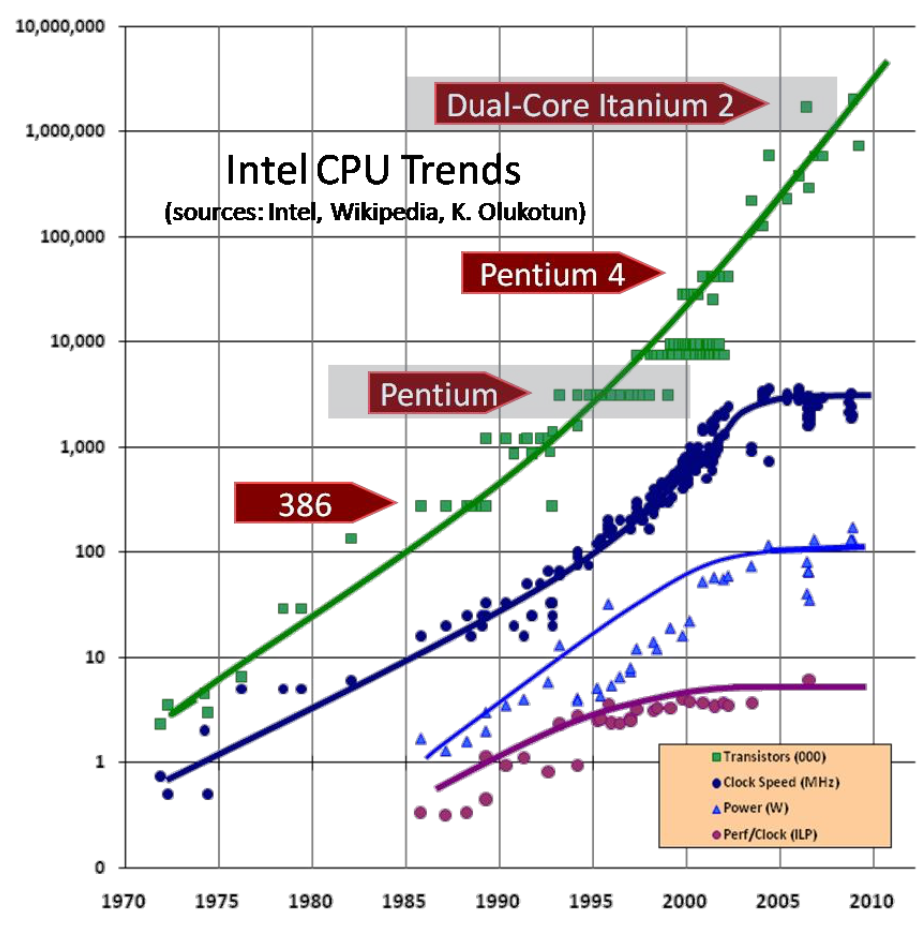
이에 반해 GPU는 매우 단순한 구조로 다루기 쉽고, 아직 모든 구조에 대해서 최적화가 완료되지 않아서 급격한 성장이 일어나고 있다.
## Example Program
다음과 같이 input x(x는 벡터 또는 스칼라일 수 있음)에 대한 사인 함수의 테일러 전개를 C언어로 구현한 코드가 있다. 이때 compiler가 프로그래밍 언어를 어셈블리어로 변환한다. 어셈블리어로 변환된 코드는 여러 줄의 인스트럭션으로 구성되며 다양한 ISA(Instruction Set Architecture)중 하나를 따를 것이다.
 |
 |
## Running on Single CPU

이제 위의 단일 CPU를 사용해서 어셈블리어를 어떻게 실행시키는지 알아보도록 하자. Computer Architecture이나 Operating System의 선수 지식이 있다면 더 이해하기 쉬울 것이다.
Register
CPU 안에 있는 작고 빠른 메모리로, 간단한 계산이나 작은 데이터 저장 등 다양한 작업에 사용된다.
Program Counter
CPU가 다음에 실행할 명령어의 메모리 주소를 가리키는 레지스터로, PC 전용으로 사용하도록 할당된 레지스터가 존재한다. 명령어가 실행 될 때마다 자동으로 증가하여 다음 줄을 실행 할 수 있도록 한다.
Stack Pointer
스택은 함수 호출 시에 return을 할 주소 즉, 함수를 빠져나갔을 때 이어서 실행할 수 있도록 반환되는 주소를 저장하거나 지역변수를 저장할 때 사용된다. 스택 포인터는 가장 최근에 저장된 데이터의 위치를 가리킨다. 스택은 LIFO(Last In First Out) 구조이므로 스택 포인터는 스택의 가장 높은 주소를 가리킬 것이다.
Fetch / Decode
Fetch는 CPU가 실행할 명령어를 메모리에서 가져오는 단계이다. PC(Program Counter)가 현재 실행할 명령어의 주소를 가리키고 해당 명령어를 가지고 온다. 위의 어셈블리어로 변환된 코드 한줄을 Instruction 또는 명령어라고 부른다. 코드가 담긴 파일을 컴퓨터가 읽으면 Stack 해당 코드를 저장하고 그 Stack의 특정 주소를 가리키면 해당 주소에 해당하는 명령어 한줄을 읽어오는 것이다. 말그대로 명령어를 패치하는 단계이다.
Decode는 Fetch해서 읽어온 명령어를 해석해서 어떤 연산을 수행해야 하는지 파악한다. 명령어가 어떤 것인지에 따라서 필요한 동작또한 달라질 것이다. 예를 들어서 Decode해서 읽어온 명령어가 mul r1, r0, r0 라고 해보자. 이는 r0과 r0 레지스터에 저장되어 있는 값을 곱하고 r1에 저장하라는 의미이다(r0의 제곱한 값을 r1에 저장하라는 뜻). 이러한 의미를 32bit 크기로 분해하고 CPU의 ALU 유닛에 전달해서 실행(Execute)할 준비를 마친다.
ALU(Execute)
ALU(Arithmetic Logic Unit)는 말 그대로 연산 및 실행을 하는 장치이다. Decode 이후에 실제 계산을 수행하고 그 결과를 레지스터나 메모리에 저장한다.
Execution Context
Execution Context는 한국어로 직역 했을때 실행 문맥 즉, 실행할 당시의 모든 정보를 포함하는 문맥을 저장하는 주소 공간이다. 왜 이러한 공간이 존재하는가? 컴퓨터는 동시에 여러가지 일을 처리할 수 있도록 설계되어있다. 하지만 실제로 동시에 모든것들을 처리하는 것은 아니다. 정말 빠르게 프로세스 또는 스레드라고 불리는 작업들을 바꿔가면서 일의 우선순위를 정하고 처리한다. 만약에 a라는 일을 하다가 b라는 일이 요청되어서 a를 실행하면서 갖고 있던 모든 정보를 다 버린다고 생각 해보자. 다시 a 일로 복귀 했을 때 처음부터 모든 일을 다 시작해야 할 것이다. 이것이 Execution Context의 목적이다.
## Running on Single CPU with Superscalar
Superscalar
일반적 파이프라인 기법의 확장을 통해 CPU의 속도를 향상시키기 위한 컴퓨터 구조 설계 방식을 지칭한다. Out-of-order control logic, fancy branch predictor, memory pre-fetcher 등의 일정 조건을 만족하는 파이프라이닝 방식으로, 장단점이 존재한다. 기본적으로 병목현상을 해결하고 병렬성을 높이고자 고안한 아이디어이다. ILP를 구현하는 방법의 일종이다.
Single CPU로 Superscalar를 구현하려면 어떻게 해야할까? 조건을 충족하기 위해 아래의 하드웨어적인 기법을 몇가지 추가한다.

Data Cache는 CPU와 메모리 사이의 속도 차이를 줄이기 위해서 자주 사용하는 데이터나 명령어를 임시로 저장하는 고속 메모리이다. CPU가 메모리에 접근할 때 많은 시간이 소모되는데, 이 때 하나의 데이터를 가져오기 위해서 불필요한 여러번의 접근을 줄이기 위해서 미리 데이터를 가져와서 저장해 놓는다는 의미이다. 위치와 계층에 따라서 L1, L2, L3로 구성되며 접근 속도가 빠를수록 즉, CPU에서 가까울수록 용량이 작다.
Out-of-Order Control Logic은 명령어와 데이터 사이의 의존성을 고려하여 꼭 순차적으로 실행되지 않더라도 가능한 연산을 먼저 수행시키도록 하는 방식이다. CPU 자원 즉 파이프라인 사이클을 최대한 효율적으로 사용할 수 있다.
Fancy Branch Predictor는 조건문이나 루프 같이 Program Counter가 분기될 때 다음에 실행될 명령어를 미리 예측해서 파이프라인을 유지하는 역할을 한다.
Memory Pre-Fetcher는 CPU가 데이터나 명령어를 필요로 하기 전에 미리 메모리에서 가져와 캐시에 저장해두는 역할을 한다. 메모리 접근 시간을 줄이고 성능을 향상시킨다.
## Idea of Dual Core
위에서 구현한 수퍼스케일러 등의 강력한 하나의 코어를 사용하는 대신, 여러개의 중간 성능 코어로 병렬성을 활용하는 것이 더 효율적인 연산이 존재 할 것이다. 이를 구현 한 것이 두개 이상의 CPU 코어로 이루어진, 듀얼코어이다. 서로 종속성이 없는 두가지의 연산을 서로 다른 CPU 코어에서 하나씩 맡아서 연산한다면, 속도가 훨씬 빨라지고 하나의 CPU가 가지는 부하도 덜 할 것이다!

그렇다면 듀얼코어 말고 트리플, 쿼드러플,.... 엄청나게 많은 코어를 가지는 멀티 코어 연산은 훨씬 더 효율적이라고 생각 할 수 있다.

## SIMD(Single Instruction Multiple Data)
SIMD는 단일 명령어 다중 데이터라는 의미로, 하나의 명령어로 서로 다른 데이터 요소를 동시에 핸들링하는 것에 영감을 받은 구조이다. ALU 유닛을 여러개 복사한 것이 기본적인 구조이고, 하나의 명령어로 여러개의 데이터를 처리하겠다는 아이디어이다. 이렇게 보면 감이 오지 않겠지만, 다음 설명을 보면 감이 올것이다.
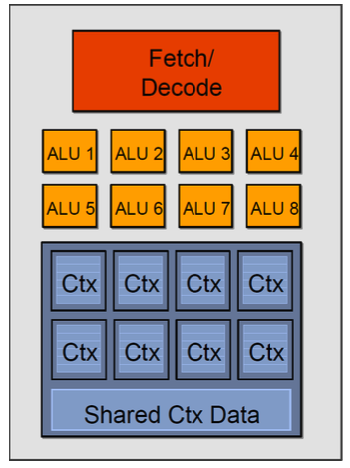
하나의 연산에서 여러개의 데이터를 처리 하는 경우는 무엇이 있을까? 바로 벡터 등의 행렬 연산이다. 행렬은 각 행과 열끼리 메모리상에 연관되어 있지만, 서로 다른 줄에서 한꺼번에 불러와 접근하는 경우가 있다. 즉, 각 행이나 열을 독립적인 데이터 요소로서 생각할 수 있다. 아래의 예시를 보면 [[0, 7], [1, 7], [2, 7], [3, 7]]의 (2,4) 크기를 갖는 행렬이 프로그램의 input으로 들어왔다. 이때 각 행을 서로 다른 ALU가 하나씩 맡아서 처리한다. 이것이 SIMD 프로세서의 동작 원리이다. 굉장히 간단하다! 이렇게 SIMD는 데이터 병렬성을 여러개의 ALU 유닛을 사용하여 구현했다.
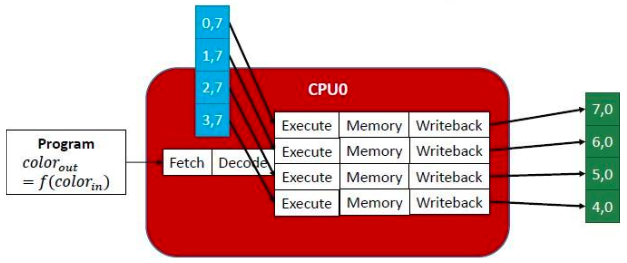
SIMT(Single Instruction Multiple Threads)
SIMT는 단일 명령어 다중 스레드라는 의미로, GPU의 기본적인 구조가 되는 아키텍쳐이다. 사실 NVIDIA에서 제창한 단어로서 SIMD와 명확하게 구분되어 사용되지는 않는다고 한다. 기본 원리는 SIMD와 매우 동일하다. 하나의 명령어를 fetch해서 데이터를 병렬적으로 계산한다는 아이디어는 같지만, 서로 다른 스레드가 존재하고 각 스레드마다 파이프라인이 독립적으로 존재하기 때문에 조금 더 다양하고 고차원적인 데이터 형태에 대처할 수 있는 능력이 있다.

# GPU Architecture
## NVIDIA GPU
Tesla (2006)
앞서 말했던 CPU와 SIMT의 구조를 바탕으로 GPU 구조에 대해서 이해를 해보자. 밑의 그림은 엔비디아의 테슬라 GPU 구조이다. Special Function Unit(SFU)는 사인 코사인 등 일반적인 ALU로 처리하기 어려운 특별한 함수들을 처리하기 위한 유닛이다. Register File은 GPU에 존재하는 Register들의 집합 공간이다. Streaming Multiprocessor(SM)은 이러한 구조들의 집합체를 말한다 병렬 처리의 기본 단위이다. 이러한 GPU의 단위들을 꼭 CPU와 똑같이 매칭시켜서 생각할 필요는 없다. 뒤에서 더 살펴볼 예정이지만, GPU는 GPU만의 체계가 있기 때문이다.

Maxwell (2012)
Maxwell은 Tesla와 큰 차이가 없다. SFU가 늘어나고 몇가지 복잡한 하드웨어들이 추가되었지만, 기본적인 아이디어는 동일하다.


Ampere (2020)
NVIDIA GPU에는 CUDA Core과 Tensor Core이 들어간다. CUDA Core는 CPU 내부에 존재하는 Core가 하는 일과 유사하지만, Tensor Core은 NVIDIA에서 행렬 곱셈 프로세스를 위해서 개발한 처리 장치로, 다양한 테크닉을 활용해서 행렬 연산을 가속한다. 추후에 더자세하게 배울 예정이다.
Ampere는 Tensor Core를 단순하게 GPU 구조 안에 추가 함으로써 기존의 GPU보다 에너지 효율과 성능을 10배 가까이 높였다. Tensor Core만으로는 연산을 할 수 없고, GPU의 일반 Core와 같이 특정한 몇가지의 연산의 효율을 비약적으로 올렸다.

## CUDA Programming Model
Streaming Multiprocessor(SM)
Streaming Multiprocessor는 NVIDIA에서 개발한 GPU의 구조에서 핵심적인 구성 요소로, 연산의 병렬처리를 수행하는 기본 단위이다. 각 GPU는 복제된 여러개의 SM을 포함하고, 각 SM은 다수의 CUDA Core를 포함하며 각 CUDA Core는 스칼라 연산을 수행한다.

GPU는 일반적으로 CPU와 독립적으로 작업을 수행할 수 없다. GPU는 다음과 같은 작업 수행 절차를 따른다. CPU와 GPU는 PCI Bus로 연결되어 있다.
- CPU Memory에서 GPU Memory로 입력 데이터를 복사한다
- GPU Program을 로드하고 실행하며, 성능향상을 위해서 실행중에 데이터를 캐싱한다
- GPU에서 연산이 끝난 값을 CPU로 전달한다

지금까지 GPU의 하드웨어 구조에 대해서 간략하게 살펴보았다. GPU 구조에서 Software와 Hardware는 다음과 같이 매핑된다.
- 쓰레드는 하나의 스칼라 프로세서에 의해서 실행된다. 즉, 스칼라 프로세서는 하나의 쓰레드를 실행하는 단위이다.
- 여러개의 쓰레드가 묶여서 쓰레드 블록이 되고, 멀티 프로세서에 의해서 쓰레드 블록이 처리된다.
- 여러개의 쓰레드 블록이 묶여서 그리드가 되고, 멀티프로세서가 복제된 하나의 GPU 디바이스에 의해서 그리드가 처리된다.

## Grid, Block and Thread
Thread (스레드)
CUDA 장치에서 가장 기본적인 실행 단위이고, 여러가지 스레드가 병렬로 실행된다. 데이터를 병렬로 처리하여 연산 속도를 향상시킨다. 기존에 알고있는 CPU 스레드와의 차이가 존재하는데, GPU는 CPU 스레드에 비해서 자원 사용이나 스위칭 비용 등이 훨씬 적어 병렬 처리 능력이 효율적이다. CPU와 마찬가지로 각각이 독립적인 레지스터 메모리를 가진다.
Thread Block (스레드 블록)
함께 실행되는 스레드의 그룹을 의미한다. 하나의 멀티프로세서에서 공유 메모리를 사용할 수 있다. 최대 몇백개에서 몇천개의 스레드를 포함할 수 있으며, 스레드 블록 안에 있는 스레드들은 서로 Shared Memory를 사용해서 데이터를 공유하고 동기화 할 수 있다. 다른 스레드의 실행을 대기하는 것도 가능하다. 스레드 블록이 두개의 서로 다른 SM에 쪼개져서 들어가는 경우는 없으므로 유의하자.
Grid (그리드)
스레드 블록의 집합이며, 하나의 CUDA 커널을 논리적으로 병렬 실행하는 단위이다. GPU의 전체 작업 영역이다. 각 스레드 블록끼리 직접적인 데이터 공유는 불가능하지만, Global Memory를 통해서 간접적인 데이터 교환이 가능한 것이 특징이다. Global Memory는 Shared Memory와 다른 개념이니 주의하자.
이렇게 호스트가 존재할때 여러가지 커널이 실행되는데, 커널 하나에 그리드 하나가 차지하고, 그리드 안에는 여러개의 쓰레드 블록이 존재하며, 쓰레드 블록 안에는 여러개의 쓰레드가 존재한다. 쓰레드들은 같은 블록 안에서 Shared Memory로 메모리를 공유하지만 다른 블록의 쓰레드와는 공유할 수도 협업할 수도 없다.

## Terminology Review
Warp (워프)
워프는 물리적으로 동시에 실행되는 스레드의 그룹이다. 그리고 무엇보다 중요한 것은, 스케쥴러로 인해서 한 사이클 안에 한 워프의 실행은 무조건 보장된다. 즉, 32개 스레드가 동시에 병렬 실행 되는 것이 일종의 타임슬롯처럼 무조건 보장되는 것이다. CPU의 Job Scheduler에 의해서 스레드와 프로세스가 일정 클락 사이클만큼 실행 보장되는것과 굉장히 유사하다.
예를 들어서 한 스레드 블록 안에 1024개의 스레드가 존재한다고 생각 해보자. 이때 1024개가 한 사이클 안에 전부 다 실행될 수 있을까? 절대 없다. 따라서 스레드 블록을 워프 단위 32개씩 쪼개서 실행한다. 이때 워프는 하드웨어의 SM, 스레드블록과는 큰 상관이 없다. 스케쥴러에 의해서 스레드에 작업이 할당되고, 하나의 워프가 스케쥴링의 최소 단위가 된다. 하나의 워프에 할당된 instruction은 항상 그 워프에 의해서 실행된다.
Half-Warp (하프 워프)
워프의 절반을 의미한다. 16개의 스레드를 포함하며, 각각의 하프 워프는 독립적으로 처리될 수 있다. 하나의 워프를 전부 다 사용할수도 있고, 하프 워프로 쪼개서 한 사이클에 독립적으로 처리되는 두개의 작업을 실행할 수도 있는 것이다.
아래 그림을 보자. 워프 스케쥴러에 의해서 워프들이 스케쥴링되고 워프 하나당 하나의 명령어를 실행하고 있는것을 볼 수 있다.

이러한 Warp의 특성은 한 사이클에 무조건 하나의 워프가 돌아가게 되어있다. 따라서 Branch 즉, 분기가 일어나면 비효율적인 GPU 프로그래밍이 될 수 있다. 아래의 그림을 살펴보자. 하나의 사이클에 대해서 어떤 스레드는 x가 0보다 클때의 작업을 할당받았고, 다른 스레드들은 x가 0보다 작거나 같을때의 작업을 할당 받았다. Branch가 True일 때는 전체 워프의 스레드들 중에서 3개만 실행이 되었고, Branch가 False일 때는 전체 워프의 스레드들 중에서 5개만 실행이 되었다. 이는 워프에서 실행할 수 있는 스레드들을 사이클마다 낭비하는 스케쥴링이라고 볼 수 있다. 따라서 GPU Programming을 할 때는 Branch를 최대한 만들지 않는것이 좋다.

## GPU Memory Hierarchy
GPU를 메모리 계층구조로 살펴본다. 그 전에, 먼저 용어에 대한 정리를 해보도록 하자.
- Register는 접근이 매우 빠르고 작은 로컬 메모리이다. 계산, 데이터 저장 등 다양한 용도로 사용된다.
- Caches(캐시)는 메모리에 접근할 때 느린 시간을 개선하기 이해서 작고 빠른 임시 저장소를 만들어 둔 것이다. 다양한 종류가 있다.
- Global Memory는 GPU에서 서로 다른 그리드끼리 메모리를 간접적으로 공유할 수 있는 공간이다.
일반적으로 Cache, Main memory, Stroage 순으로 용량이 크고 접근 시간이 오래 걸린다.

GPU Memory Hierarchy를 더욱 자세히 알아보자.
각 스레드는 작고 접근이 빠른 레지스터와 조금 더 큰 로컬 메모리를 할당 받는다.

스레드 블록은 포함하고 있는 스레드끼리 데이터를 공유할 수 있는 Shared Memory를 갖는다.

모든 블록들 즉 하나의 그리드들은 그리드 사이에 간접적으로 공유할 수 있는 Global Memory를 갖는다.

이 외에도 그리드가 가지는 몇가지 특수한 메모리가 있다. 더욱 자세하게 알아보도록 하자.
- Shared Memory
캐시로 사용되며 SM안의 스레드 블록 사이에서 데이터를 공유하기 위해서 사용된다.
총 합한 메모리 bandwidth가 1TB/sec이다.
16KB per SM을 갖는다. - Constant Memory
변수가 아닌 상수를 저장하기 위해서 사용되며, 커널(그리드)를 실행하는 호스트에 의해서 작성되어 GPU가 읽어오기 위하여 캐시 된다. - Texture Memory
이미지 처리 및 렌더링에 사용되는 데이터를 캐시하는 메모리이다.

[인공지능 하드웨어] 4 - GPU Architecture(2)
# 들어가며CPU와 GPU의 구조에 대해서 자세하게 배운다. CPU 구조를 조금 더 알아보고 CPU Performance Optimization을 토대로 GPU Performance Optimization을 중점적으로 알아본다. 컴퓨터 구조 관련한 배경지식이
kmuhan-study.tistory.com
국민대학교 권은지 교수님의 인공지능 하드웨어 강의를 수강하며 정리한 내용입니다.
Slides Provided
임베디드 시스템 프로그래밍 - Eunhyeok Park
딥러닝 최적화 - Eunhyeok Park
'AI > AI Hardware' 카테고리의 다른 글
| [인공지능 하드웨어] 6 - Deep Learning Optimization(Convolution Lowering, Systolic Array) (6) | 2024.10.11 |
|---|---|
| [인공지능 하드웨어] 5 - GPU Performance Optimization(Matrix Tiling, Tensor Core) (8) | 2024.10.09 |
| [인공지능 하드웨어] 4 - GPU Architecture(2) (3) | 2024.10.07 |
| [인공지능 하드웨어] 2 - DNN Computation (3) | 2024.09.23 |
| [인공지능 하드웨어] 1 - Introduction to DNN (3) | 2024.09.23 |