# 들어가며
DNN(Deep Neural Networks)가 어떻게 계산되는지 알아보고, 하드웨어에서 어떻게 처리될지 행렬 수준에서 이해해 보도록 하자. 이전 글은 다음 링크의 블로그 포스트를 참고하면 된다.
[인공지능 하드웨어] 1 - Introduction to DNN
# 들어가며인공지능 연구가 거듭될수록 하드웨어가 중요해지고 있다. vLLM, CXL 메모리 같이 on-device AI를 위한 새로운 low-level 인공지능 하드웨어 관련 기술이 발전하고 있다. 1. 신경망이 무엇인지
kmuhan-study.tistory.com
# AI Hardware
인공지능 하드웨어의 동향에 대해서 알아보자. 인공지능 하드웨어(GPU)의 종류는 Cloud, Edge로 나눠지며, Edge는 그 쓰임새에 따라서 다른 형태로 출시된다.
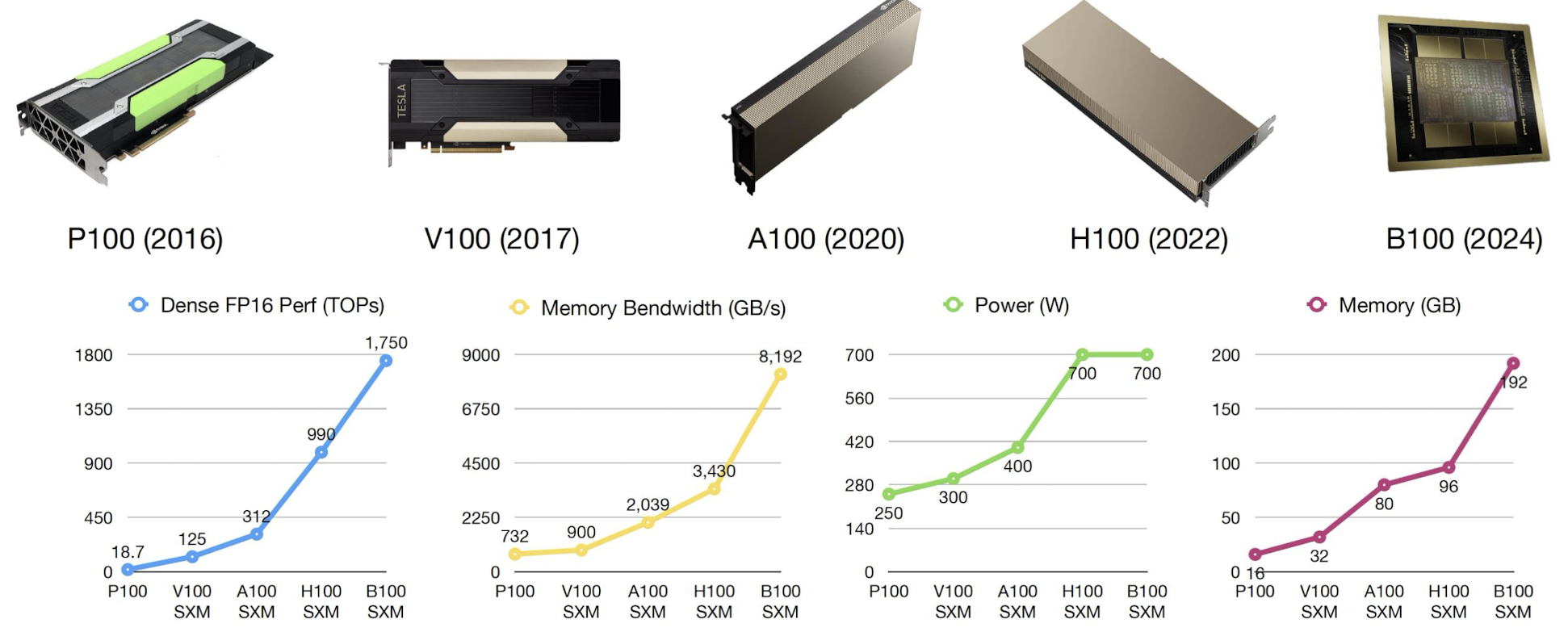
### Cloud Hardware
클라우드 하드웨어의 대표주자 엔비디아의 머신들이다. 2024년 기준으로 하반기에 출시 예정인 Blackwell의 엄청난 성능 향상이 돋보인다. 고무적인것은, 성능은 거의 모든 분야에서 약 두배정도 향상되었지만 Power 즉, 에너지 소모는 이전 모델과 동일하다는 것이다.
### Edge Hardware
다음은 퀄컴 Hexagon에서 출시한 DSP(Digital Signal Processor) 제품군이다.

다음은 애플의 ANE(Apple Neural Engine)이다. M칩은 포함되지 않았지만, A칩보다 월등한 성능을 자랑한다고 한다.

이 외에도 NVIDIA Jetson, Microcontroller 등 다양한 인공지능 하드웨어가 존재한다. Cloud AI와 Edge AI의 격차는 굉장히 크다.

현재 인공지능의 트렌드는 더 무거운 모델, 더 많은 데이터, 더 많은 컴퓨팅 리소스이다. 대표적으로 GPT, BERT같은 LLM들이 있을 것이다. 하지만 이런 연구 트렌드는 거대기업의 자본 없이는 성과를 내기 힘들며, 대부분의 연구들은 작은 컴퓨팅 리소스로 경량화된 모델을 학습시켜 실험 결과를 작성하거나, 기존의 모델을 경량화 하려는 노력을 하고 있는 추세이다.
# Tensor Operation

n차원 텐서는 세상에 존재하는 모든 n개의 축을 가지는 차원에 대한 데이터 구조를 말한다. 위의 그림을 보면 이해가 쉽다. 우리가 흔히 점이라고 말하는 스칼라는 0차원 텐서고, 크기와 방향을 가지는 벡터는 1차원 텐서이다.
텐서 연산은 입력이 텐서이고, 출력도 텐서인 연산이다. 벡터가 들어가서 스칼라가 나와도 매트릭스가 나와도 모두 텐서 연산인 것이다.
또한, 신경망은 텐서 연산의 유방향 그래프(Directed Graph)로 볼 수 있다. 그냥 교환되는 데이터 형태가 텐서인 것 유방향 그래프라고 생각하면 이해가 쉽다. MatMul은 Matrix Multiplication의 약자로, 행렬곱이다. 선형대수 시간에 배우는 그 행렬곱이 맞다.

## Tensor Operation in HW
그렇다면 하드웨어 안에서 텐서 연산은 어떻게 되는것일까? 대부분의 기존 하드웨어들은 벡터 연산(1차원 텐서)와 행렬 연산(2차원 텐서)만을 지원한다. 즉, 3차원 텐서 이상의 연산은 한번에 지원하지 않는다는 뜻이다. 이유는 메모리 장치들이 데이터를 한줄씩 접근하는 방법을 사용하기 때문이다. 따라서, 행렬을 저장 할 때 데이터를 저장하는 방향이나 순서가 매우 중요하다!

따라서 고차원 텐서 연산을 수행 할 때는 저차원의 시퀀스(Sequence, 낮은 수준의 데이터를 보통 시퀀스라고 표현)로 풀어내거나 재구성 해서 하드웨어 가속을 활용할 필요가 있다. 3차원의 텐서는 3개의 방향으로 쪼개서 시퀀스를 만든 후 연산하면 더 빠르게 연산할 수 있을 것이다. 4차원은 두번 쪼개야 할 것이고, 5차원은 3번 쪼개면 될것이다. 이런식으로 하드웨어 가속을 활용하는 방법이 있다.

## DNN Computation
MLP의 행렬 연산과 컨볼루션 네트워크의 행렬 연산은 자세히 다루지 않겠다. 다만, 굉장히 많은 좋은 내용의 블로그들과 유튜브 강의들이 있으니, 꼭 찾아보고 한번쯤은 손이나 머리로라도 따라가면서 직접 유도 해 보길 바란다.
아래는 MLP에서 활성화 함수 행렬과 가중치 행렬을 MatMul하는 과정을 그림으로 나타낸 것이다. (x,y) * (y,z) = (x,z)의 행렬 크기가 계산 될 것이다. 이때, 활성화 함수 행렬이 앞에오고 가중치 행렬이 뒤에 온다. 활성화 함수 행렬은 row-major 방식으로 메모리에 저장되어야 할 것이며, 가중치 행렬은 column-major 방식으로 저장되어야 할 것이다. 이유는, 메모리 참조가 발생 할 때 보통 한줄을 통째로 읽어오기 마련이기 때문이다. 따라서, 데이터를 저장 할 때는 순서와 방향이 매우 중요하다.

[인공지능 하드웨어] 3 - GPU Architecture(1)
# 들어가며CPU와 GPU의 구조에 대해서 자세하게 배운다. 컴퓨터 구조 관련한 배경지식이 있으면 이해하기 편하므로 글을 읽다가 이해가 되지 않는다면 관련 블로그 포스트나 유튜브를 찾아보는
kmuhan-study.tistory.com
국민대학교 권은지 교수님의 인공지능 하드웨어 강의를 수강하며 정리한 내용입니다.
Slides Provided
임베디드 시스템 프로그래밍 - Eunhyeok Park
딥러닝 최적화 - Eunhyeok Park
'AI > AI Hardware' 카테고리의 다른 글
| [인공지능 하드웨어] 6 - Deep Learning Optimization(Convolution Lowering, Systolic Array) (6) | 2024.10.11 |
|---|---|
| [인공지능 하드웨어] 5 - GPU Performance Optimization(Matrix Tiling, Tensor Core) (8) | 2024.10.09 |
| [인공지능 하드웨어] 4 - GPU Architecture(2) (3) | 2024.10.07 |
| [인공지능 하드웨어] 3 - GPU Architecture(1) (7) | 2024.10.04 |
| [인공지능 하드웨어] 1 - Introduction to DNN (3) | 2024.09.23 |